
【全网首发】盘点内核中常见的CPU性能卡点原创
大家好,我是飞哥!
我们的应用程序都是运行在各种语言的运行时、操作系统内核、以及 CPU 等硬件之上的。大家平时一般都是使用Go、Java等语言进行开发。但这些语言的下面是由运行时、内核、硬件等多层支撑起来的。
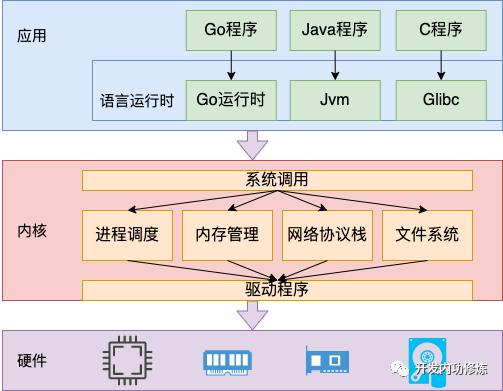
其实,内核开发者们也都知道内核运行的过程中,哪些开销会比较高。所以老早就给我们提供了一种名为软件性能事件的支持。以方便我们应用的开发者来观测这些事件发生的次数,以及发生时所触发的函数调用链。
一、软件性能事件列表
通过 perf 的 list 子命令可以查看到当前系统都支持哪些软件性能事件。
# perf list sw
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
context-switches OR cs [Software event]
cpu-migrations OR migrations [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
其中上面命令中的 sw 是 software 的简称,其实指的就是内核。下面的列表列明了一些影响性能的事件,我们挨个来解释。
alignment-faults
这个指的是对齐异常。简单来说,当CPU访问内存地址时,如果发现访问的地址是不对齐的,那内核向内存请求数据的时候可能一次 IO 不够,还得再触发一次 IO 才能把数据给读取回来。对齐异常会增加本来不需要的内存 IO,必然会拖累程序运行性能。
如果你还没理解的话,可以看下图。在下图中 0-63 和 64-127 地址的数据都可以由一次内存 IO 完成。但如果你的应用程序非得从 40 位置开始要个长为 64 的数据。那就是不对齐的。

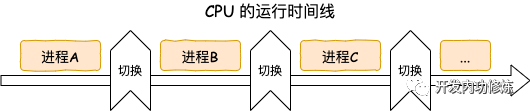
context-switches
进程上下文切换。在进程/线程切换究竟需要多少开销?一文中我们专门介绍过进程上下文切换的开销。平均每次切换都得 3-5 us。这对于运行的飞快的操作系统来说,已经是一个非常长的时间了,而更为关键的是,对于用户程序来说,这段时间完完全全就是浪费的。频繁的上下文切换还会进一步导致 CPU 缓存命中率变差,拉高 CPI。
cpu-migrations
进程如果每次调度的时候都能够在同一个CPU核上执行,那大概率这个核的L1、L2、L3等缓存里存储的数据还能用的上,缓存命中率高可以避免对数据的访问穿透到过慢的内存中。所以内核在调度器的实现上开发了wake_affine机制来使得调度尽可能地使用上一次用过的核。
但如果进程在调度器唤醒的时候发现上一次使用过的核被别的进程占了,那该怎么办。总不至于不让这个进程唤醒,硬等上一次用过的这个CPU核吧。给它分配一个别的核让进程可以及时获得CPU也许更好。但这时就会导致进程执行时在CPU之间跳来跳去,这种现象就叫做任务迁移。
显然任务迁移是对CPU缓存不太友好的。如果迁移次数过多必然会导致进程运行性能的下降。
emulation-faults
emulation-faults 错误是在 QEMU 虚拟机中运行 x86 应用程序时出现的一种错误类型。x86 程序需要在 x86 架构的计算机上运行,并且依赖于该计算机的硬件架构和指令集。QEMU 作为一款模拟器,可以模拟 x86 硬件架构和指令集,但是由于模拟器与真实硬件之间存在差异,因此在运行 x86 应用程序时可能会产生 emulation-faults 错误。
page-faults
这是我们常说的缺页中断。用户进程中在申请内存的时候,其实申请到的只是一个vm_area_struct而已,仅仅只是一段地址范围。物理内存并不会立即就分配,具体的分配等到实际访问的时候。当进程在运行的过程中在栈上开始分配和访问变量的时候,如果物理页还没有分配,会触发缺页中断。在缺页中断种来真正地分配物理内存。关于缺页中断可以参考进程栈内存底层原理这篇文章。
其中缺页中断又分为两种,分别是 major-faults 和 minor-faults。这两种错误的区别在于 major-faults 会导致磁盘 IO 的发生,所以对程序运行的影响更大。
二、软件性能事件的计数统计
了解了内核中可能会影响程序运行性能的几种事件后,我们的一种需求就是看看系统中实际发生了多少次这样的事件。这个使用 perf stat 子命令就可以办到。
# perf stat -e alignment-faults,context-switches,cpu-migrations,emulation-faults,page-faults,major-faults,minor-faults sleep 5
Performance counter stats for 'sleep 5':
0 alignment-faults:u
0 context-switches:u
0 cpu-migrations:u
0 emulation-faults:u
56 page-faults:u
0 major-faults:u
56 minor-faults:u
由于上述命令我是在我手头的一台开发机上操作的,所以很多指标都为 0 ,只发生了 56 次不太严重的 minor-faults。这个命令是统计的整个系统的情况。
如果只想查看指定的程序或进程,那就在后面跟上程序名,或者通过 -p 指定进程 pid
# perf stat <可执行程序> // 统计指定程序
# perf stat -p <pid> // 统计指定进程三、软件性能事件的函数栈跟踪
很有可能在你知道你的系统某中指标发生的太多的话,你还想看看到底是那些函数调用链导致的的。这时候 perf record 命令可以帮助你进行栈的采样。
例如,如果你想看一下 context-switches 都是如何发生的,那就来采个样。
# perf record -a -g -e context-switches sleep 30
在上面的命令中,其中 -a 指的是要查看所有的栈,包括用户栈,也包括内核栈。-g 指的是不仅仅采样时要记录当前在运行的函数名,还要记录整个调用链。-e 指的是只采样 context-switches 事件。sleep 指的是采集 30 秒。命令执行完后,当前目录下会输出一个 perf.data 文件。
默认情况下,perf stat 是一秒要采集 4000 次。这会导致采集出来的 perf.data 文件过大,而且也会影响程序性能。你可以通过 -F 参数来控制采集频率。
# perf record -F 100 ...
使用 perf script 可以查看该perf.data文件中的内容。
# perf script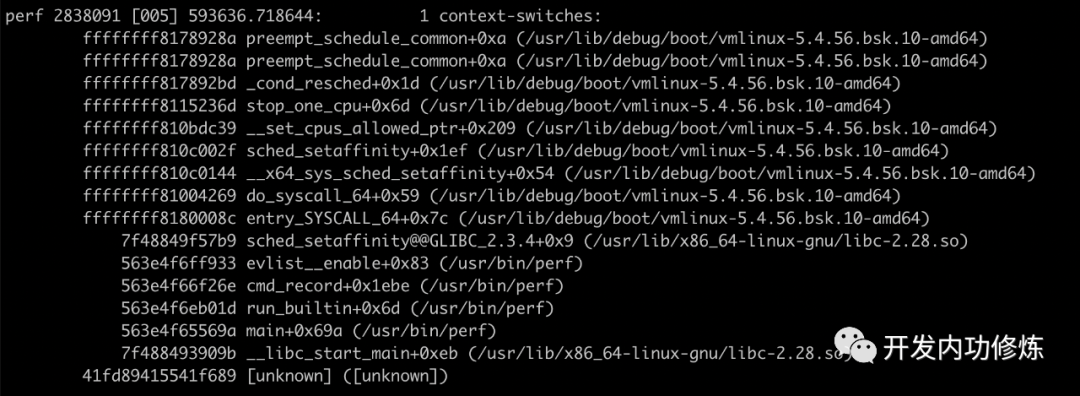
也可以使用 perf report 命令进行一个简单的统计
# perf report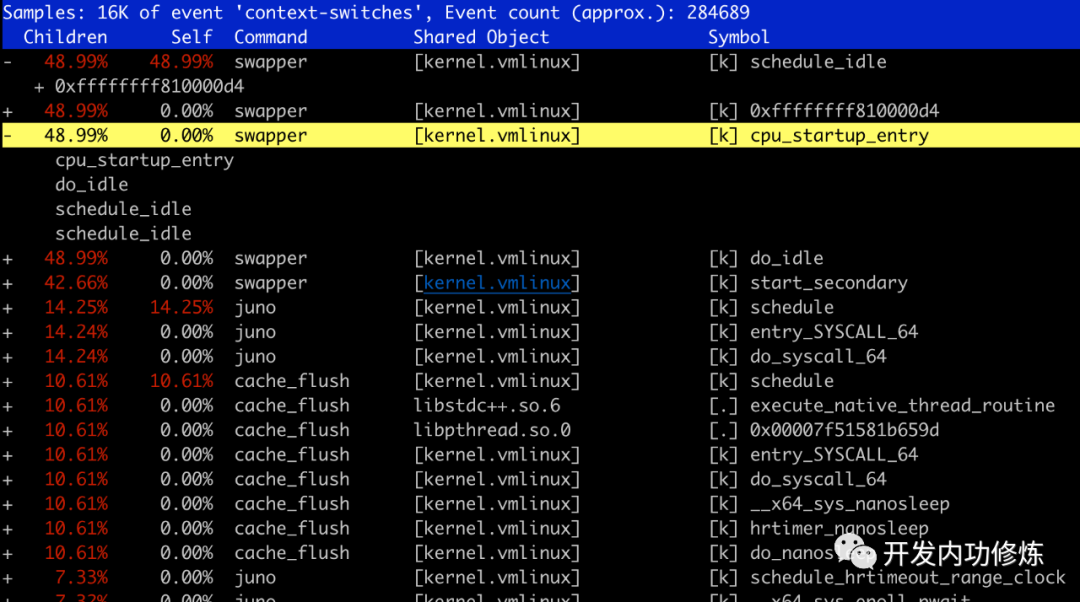
生成方式非常的简单,只需要把 FlameGraph 项目下载下来,再分别使用 stackcollapse-perf.pl 和 flamegraph.pl 两个脚本进行处理即可。
# git clone https://github.com/brendangregg/FlameGraph.git
# perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > out.svg
其中 stackcollapse-perf.pl 脚本作用是将调用栈处理为一行。行前面表示的是调用栈,后面输出的是采样到该函数在运行的次数。比如下面这个处理结果表示采样时发现 main;funcA;funcD;funcE;caculate 这个函数调用链路正在执行的次数为 554118432 次,main;funcB;caculate 这个函数调用链路正在执行的次数是 338716787。
main;funcA;funcD;funcE;caculate 554118432
main;funcB;caculate 338716787
flamegraph.pl 脚本工作原理是将 stackcollapse-perf.pl 绘制成 svg 图片。完整的火焰图工作原理这里不过多展开,大家可以看我之前发的一篇文章剖析CPU性能火焰图生成的内部原理
使用火焰图对 context-switches 内核软件事件采样结果 perf.data 进行渲染后,这样能清楚地看到哪个链路上的上下文切换发生的最为频发。
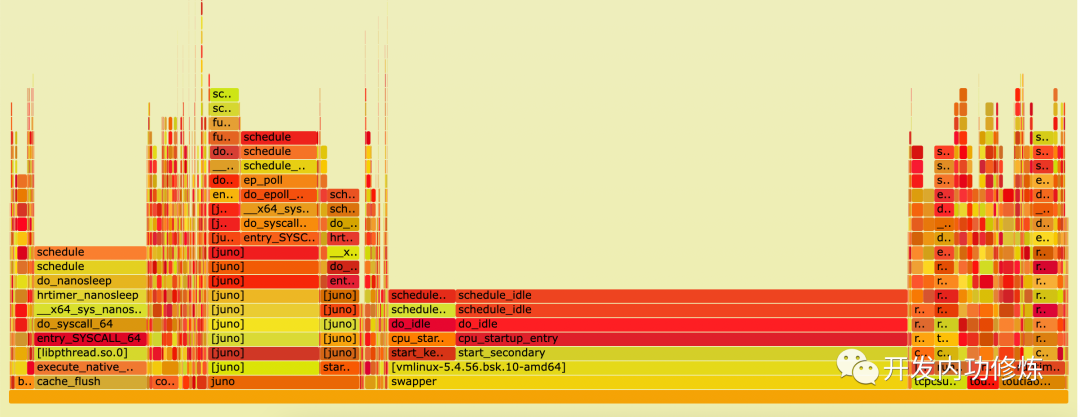
通过对火焰图的观测,就可以分析发现是哪些原因导致了最多的进程上下文切换的开销了。其它内核软件事件,例如缺页中断、CPU迁移等分析原理也一样。
欢迎把硬核的飞哥开发内功转发给你的朋友,一起学习,共同成长!


