高并发服务优化篇:详解RPC的一次调用过程原创
只要涉及到分布式服务,就绕不开RPC调用。RPC是什么,我认为大部分同学都能说出个一二三。
那么RPC一次调用,到底经历了哪些过程?
一直在说RPC耗时优化,那到底时间耗在了哪里?
本篇带大家一起来梳理清晰。再遇到面试官问RPC,直接灭丫
Part1前言 扯一扯RPC的蛋
RPC ?(Remote Procedure Call) 远程过程调用,目的是让调用远程服务的体验,就像调用本地方法一样简单。
已经有了HTTP,为啥还要实现个RPC? 首先,两者不在一个水平面,不好比较。http是一种传输协议,RPC由TCP传输协议和其他部分组成,算是一种架构;再者,效率和性能有所差异,Http相比tcp传输更耗性能;再再者,定位不同,RPC一般用于实现内部网络各服务间的高性能调用,Http一般用于跨环境的数据传输和接口调用。
RPC亘古不变的三个主题? 客户端、服务端、注册中心。后续包括服务注册、服务发现、路由寻址、序列化、IO模型等等事项,都是在围绕三者之间的合作和交互来进行的。
常见RPC有哪些?
出镜最多的要数dubbo,因为总被面试官问到;
性能优良的grpc,google出品,可以在任何环境下运行;
美团的OCTO和pigeon,一个章鱼水里游,一个鸽子天上飞;
京东之前的saf,是对dubbo的定制化开发,后面升级到了自研的jsf框架,其作者之一的章老板之前就已经是蚂蚁的P8大佬了;
蚂蚁自研的sofaRPC也有章老板的参与,由于设计初衷和蚂蚁内部的使用规模,功能丰富度和服务稳定性上,那是相当不错,目前也已经开源。
Part2 一次RPC调用的心路历程
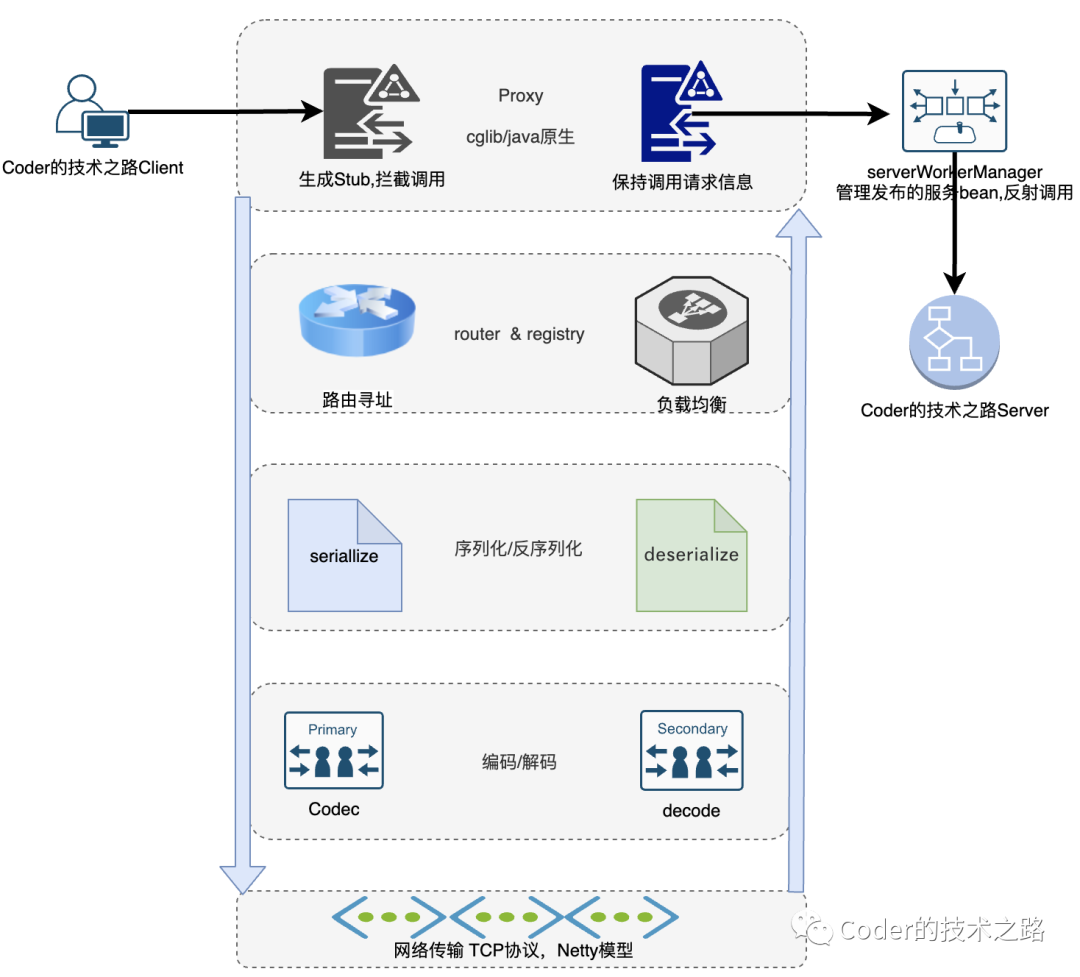
一次RPC调用的心路历程
如上图所示,一次rpc调用的过程,基本都囊括在内:
Stub 存根
处于真正调用之前。进行场景判断、条件过滤等,以dubbo为例,可以用于压测场景的数据mock等功能支持。
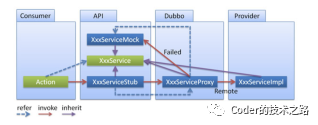
路由寻址和负载均衡
上面的图其实有点不太准确,路由寻址和服务节点的负载均衡应该是一起完成的,在选定provider之后就是直连了。图里只是为了对称一些好看。
寻址: 以safa为例,支持直连和注册中心寻址。实现方案是在地址维护器中按配置加载直连分组和集群分组,在客户端指定路由策略时,进行分别获取。
负载均衡: safa在负载算法上要支持的相对更全面一些:一致性hash、本机优先、随机负载、轮询负载、加权一致性hash、加权轮询。
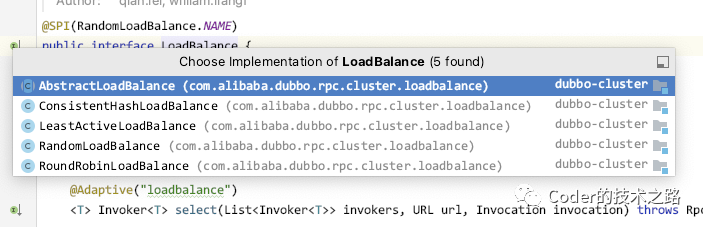
dubbo支持的负载均衡
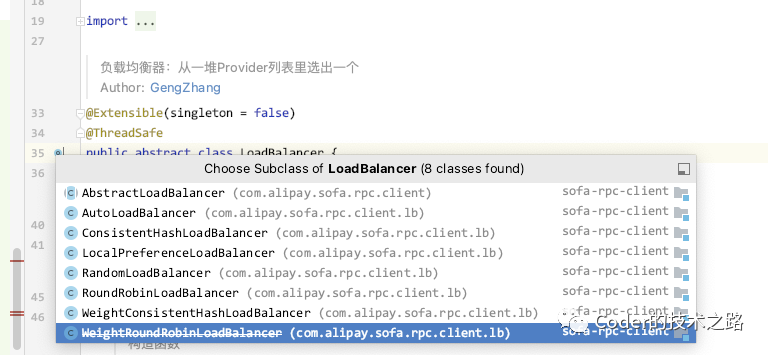
sofa支持的负载均衡
序列化和反序列化
序列化方式有很多种,包括jdk原生,kryo、hessian、protoStuff,thrift,JSON等。
这里挑两个经常使用,但是经常遇坑的来说下:
hessian: 相比于Java原生序列化,效率更高、数据更小,但是需要注意,hessian反序列化时,是将属性都取出来放到map里,因此,如果父类和子类有name相同的属性,子类的会被覆盖,因此,使用hessian时,要注意父子类不能有相同的属性名。
protoStuff: 相比Protobuf,stuff不需要写.proto文件,效率上甚至比Protobuf更快。而快的原因之一,就是因为其序列化方式是按对象属性的顺序来执行的,所以,如果顺序变了,就会反序列化失败。因此,在对使用了protoStuff序列化方式的对象新增字段时,最好是加到最后。
编码 解码
序列化之后为啥还要进行编码呢?
序列化其实是为了将待传输的对象转化成标准二进制信息,为传递做准备,同时尽可能压缩大小,方便传输。
而编码,是为了通信高效,一般的,都会加上超时策略、请求ID、网络协议等信息。
网络传输
一般大部分的RPC都选netty作为通信框架,而在底层是TCP的传输协议,而在上层,还有一层通信协议:
- Bolt,RPC私有协议,sofa所属
- Dubbo,RPC私有化协议
- Hessian,RPC公有化协议
- thrift,Facebook出品,
- 还有如RESTful等其他通信协议
通信协议的目的,是为了让中间件开发者能将更多的精力放在产品功能特性实现上,而不是重复地一遍遍制造通信框架的轮子。
Part3 RPC执行耗时都耗在了哪里
我是动图,请多给我点时间

从上图分析中可以看出一次rpc调用的具体耗时节点。
对于客户端来说,耗时主要由:建连时间 + 序列化时间 + 等待服务端处理时间组成;
对于服务端来说,耗时主要由:线程池等待时间 + 服务处理时间 + 结果序列化时间组成。
所以,对于我们一线开发,如果要对RPC耗时进行调优,最需要关注的,有客户端的路由寻址、序列化方式,有服务端的服务线程池等待、反序列化、服务端处理速率、结果序列化 这几块。
‘建连’,一般因为我们采用长连接心跳检测,是可以保证这个时间相对稳定。
比如,借鉴sofa,用增量更新的直接分组,来加速路由寻址;采用速度更快的序列化策略;调整服务端线程池到合适的大小,即能满足请求处理,又不至于增加过多的线程切换损耗;用异步调用的方式替代同步阻塞等等。
Part4 总结
本文从RPC的一次调用触发,结合一些开源的框架代码,给大家梳理了RPC的调用过程和耗时分析。让大家对RPC调用有一个更直观的体会。特别是耗时分析这一部分,对我们一线研发的开发有些直接的指导意义。
希望大家能有所得,有任何问题,欢迎留言指正、探讨~
题外话:不知道大家有没有发现,我们平常接触的框架、系统,好大一部分都来自阿里,为什么呢?一方面是因为技术确实不错,毕竟庞大的用户群和复杂的业务场景对任何系统、任何技术人都是非常好的磨刀石;不过我觉得,其他大厂的框架应该也不会差多少。只不过阿里有一群专门的人出来到处演讲、吹牛逼,我们亲切的称其为"布道者"。。。O(∩_∩)O~ 纯属瞎扯,娱乐一下~
欢迎关注我的微信公众号:Coder的技术之路