
得物关于iOS卡顿监控实施与性能调优转载
导语
卡顿就是在应用使用过程中出现界面不响应或者界面渲染粘滞的情况,用户在操作App时,会出现的页面掉帧现象,给用户直接观感受就是页面卡卡的,严重影响用户体验。得物每天面对巨大的流量,如何优化ios卡顿现象。
正文
从App使用角度来看,用户在使用上会感觉到卡顿的场景,主要分为两种:
- 用户在操作之后无法进行下一步,卡死在当前页面,过一会才恢复。(主线程阻塞)
- 滑动页面,点击操作出现反应比较慢,但用户仍可继续操作。(网络原因,子线程阻塞,如文件读写,低效计算,数据转换等)
很明显第一种情况最为致命,卡顿监测工具首先要能够监测主线程阻塞,并且能及时抓取主线程上的堆栈栈帧,上传到展示平台,便于开发者修复。
火焰图(Flame Graph)是以一个全局的视野来看待时间分布,它从底部往顶部,列出所有可能导致性能瓶颈的堆栈。在卡顿监控中,堆栈通过以火焰图形成展示,可以很清楚地发现占用时间长的方法,让开发者更能直观地发现问题点。
检测原理
Runloop检测
在 iOS应用中,主线程是默认开启 Runloop功能。Runloop 是一个 Event Loop 模型,可以让主线程处于接收消息、处理事件、进入等待等状态而不会立刻退出,其状态流如下图所示。在进入事件的前后,Runloop 会向注册的 Observer 通知相应的事件。
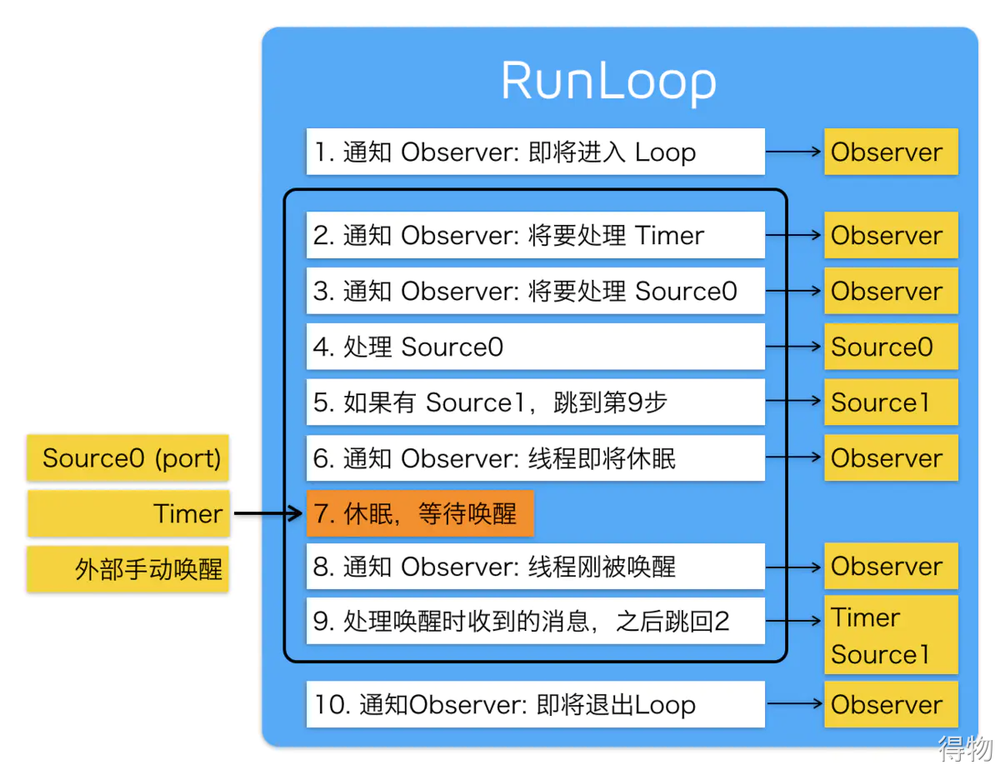
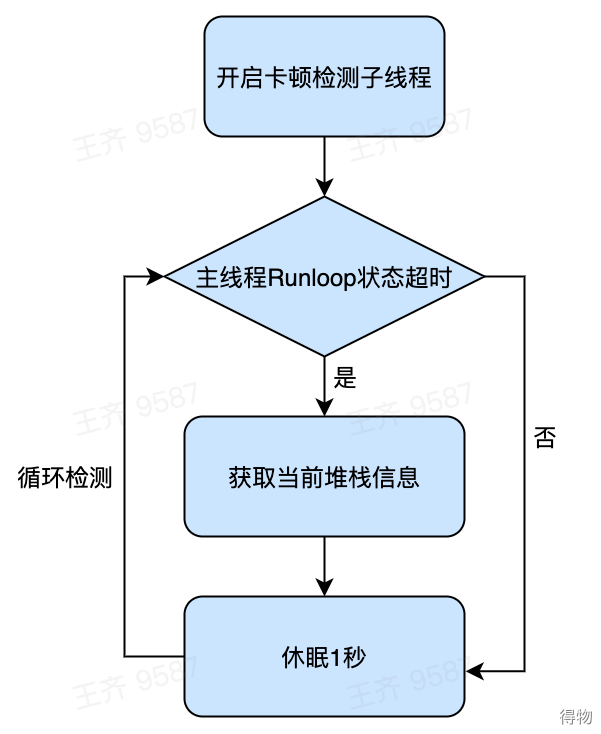
卡顿监控开辟一个子线程定时检查主线程的状态,并记录下主线程在各个运行状态的时间点,当主线程的运行状态超过一定的时间阈值后,则认为主线程卡顿。记录这时的堆栈信息,并进行相应的处理。
卡顿参数确定
目前在得物App中的卡顿监控,主线程 Runloop 超时的阈值是 3 秒,子线程的检查周期是 1 秒。每隔 1 秒,子线程检查主线程的运行状态;如果检查到主线程 Runloop 运行超过 3 秒则认为是卡顿,并获得当前的线程快照。
同时,我们也认为 CPU 过高也可能导致应用出现卡顿,所以在子线程检查主线程状态的同时,如果检测到 CPU 占用过高,会捕获当前的线程快照保存到文件中。目前得物应用中,单核 CPU 的占用超过了 80%,此时的 CPU 占用就过高了。
退火算法
为了降低检测带来的性能损耗,我们为检测线程增加了退火算法:
- 每次子线程检查到主线程卡顿,会先获得主线程的堆栈信息并保存到内存中(不会直接保存到文件中);
- 将获得的主线程堆栈与上次卡顿获得的主线程堆栈进行比对:
如果堆栈不同,则获得当前的线程堆栈信息并写入文件中;
如果相同则会跳过,并按照斐波那契数列来检查时间递增,除非获得的卡顿或主线程堆栈不再相同。
通过这种方式,避免了同一个卡顿多次写入文件的情况;同时也避免检测线程遇到主线程卡死的情况下,还不断地多次获取堆栈信息,增加CPU负担,加剧卡顿。
当检测到相同堆栈时,使用斐波那契数列时间intervalTime ,这个时间用来控制获取堆栈的间隔时间。
if (isSame) {
NSUInteger lastTimeInterval_t = intervalTime;
intervalTime = lastTimeInterval + intervalTime;
lastTimeInterval = lastTimeInterval_t;
...
} else {
intervalTime = 1;
...
}
其中时间间隔控制,获取堆栈信息的时间间隔控制策略。代码如下:
// intervalTime, 时间间隔,初始值为1,由退火算法来控制期大小
for (int i = 0; nCnt < intervalTime; i++) {
if (mThreadHandle && bMonitor) {
// periodTime == 1秒 perStackInterval == 50毫秒
int intervalCount = periodTime / perStackInterval;
if (intervalCount <= 0) {
usleep(checkPeriodTime);
} else {
// intervalCount = 20 perStackInterval = 50毫秒
//忽略其他方法执行时间 总睡眠时间为1秒
for (int index = 0; index < intervalCount; index++) {
usleep(perStackInterval);
// 获取主线程堆栈信息,并保存
...
}
}
} else {
usleep(checkPeriodTime);
}
}
堆栈信息提取
堆栈获取策略
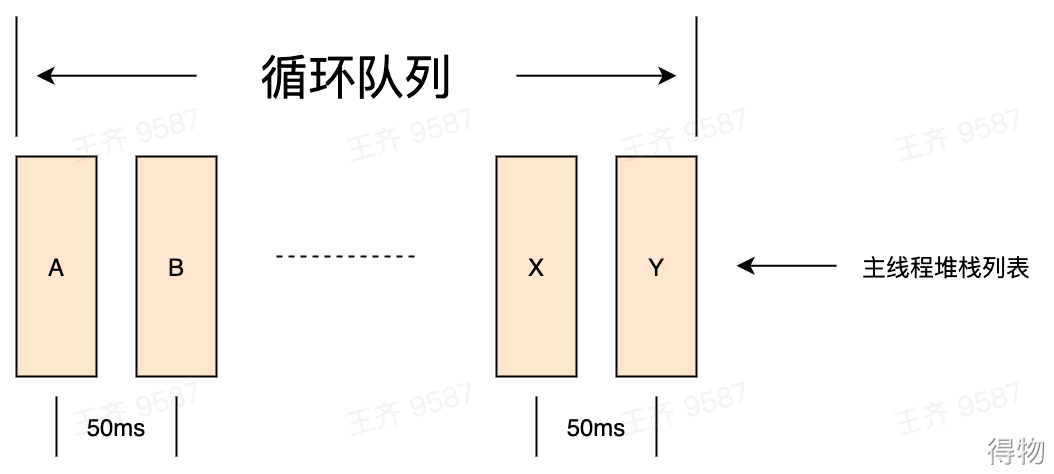
卡顿监控定时获取主线程堆栈,并将堆栈保存到内存的一个循环队列中。如下图,每间隔时间 t 获得一个堆栈,然后将堆栈保存到一个最大个数为 20(可通过平台进行配置) 的循环队列中。目前的策略是每隔 50 毫秒获取一次主线程堆栈,保存最近 20(可配置) 个主线程堆栈。这个会增加不到4%的 CPU 占用,内存占用可以忽略不计。
最耗时堆栈信息获取
子线程检测到主线程 Runloop 时,会获得当前的线程快照当做卡顿文件。但是这个当前的主线程堆栈不一定是最耗时的堆栈,不一定是导致主线程超时的主要原因。所以需要找出最耗时堆栈信息。
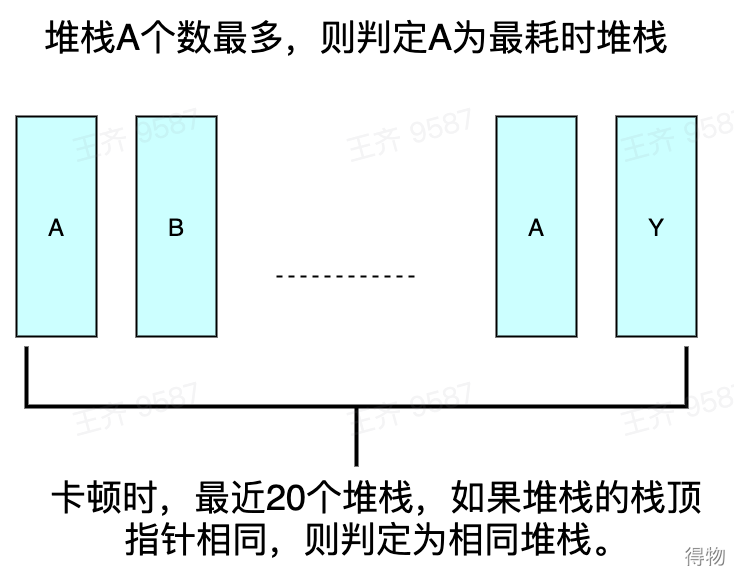
当主线程检测到卡顿时,通过对保存到循环队列中的堆栈进行回溯,获取最近最耗时堆栈。如下图,检测到卡顿时,内存的循环队列中记录了最近的20个主线程堆栈,需要从中找出最近最耗时的堆栈。卡顿监控用如下特征找出最近最耗时堆栈:
- 以栈顶函数为特征,认为栈顶函数相同的即整个堆栈是相同的;
- 取堆栈的间隔是相同的,堆栈的重复次数近似作为堆栈的调用耗时,重复越多,耗时越多;
- 重复次数相同的堆栈可能很有多个,取最近的一个最耗时堆栈。
通过以上策略,获得的最近最耗时堆栈会附带到卡顿文件中。
火焰图堆栈信息
当检测到卡顿时,获取最近所有的堆栈信息。并与最近最耗时堆栈信息一同附带到卡顿文件中。通过上传到平台上,并经过符号化解析脚本解析,最终会以火焰图形成展示出来。火焰图展示效果示例如下,函数所在的块越宽,代表耗时越长。
实施方案
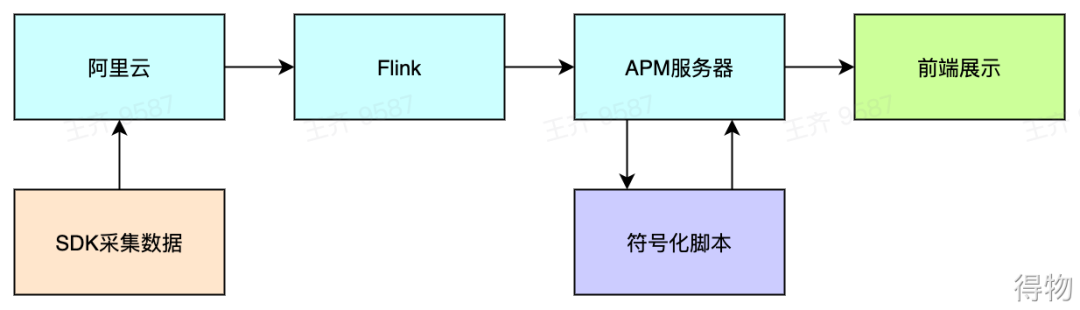
整体方案流程图
整体方案流程图如下,在App中,SDK采样了卡顿数据,并上传到阿里云平台。Flink服务则实时地把卡顿数据同步到APM服务器中,并把数据写入本地数据库中。
符号化脚本服务定时运行,不断地从APM服务器中获取未经过符号化解析的卡顿堆栈数据,经过符号化解析后,推送到APM服务器中,并落库。
前端平台从APM服务器获取经过处理后的卡顿数据,并在前端平台展示。
堆栈采样SDK设计
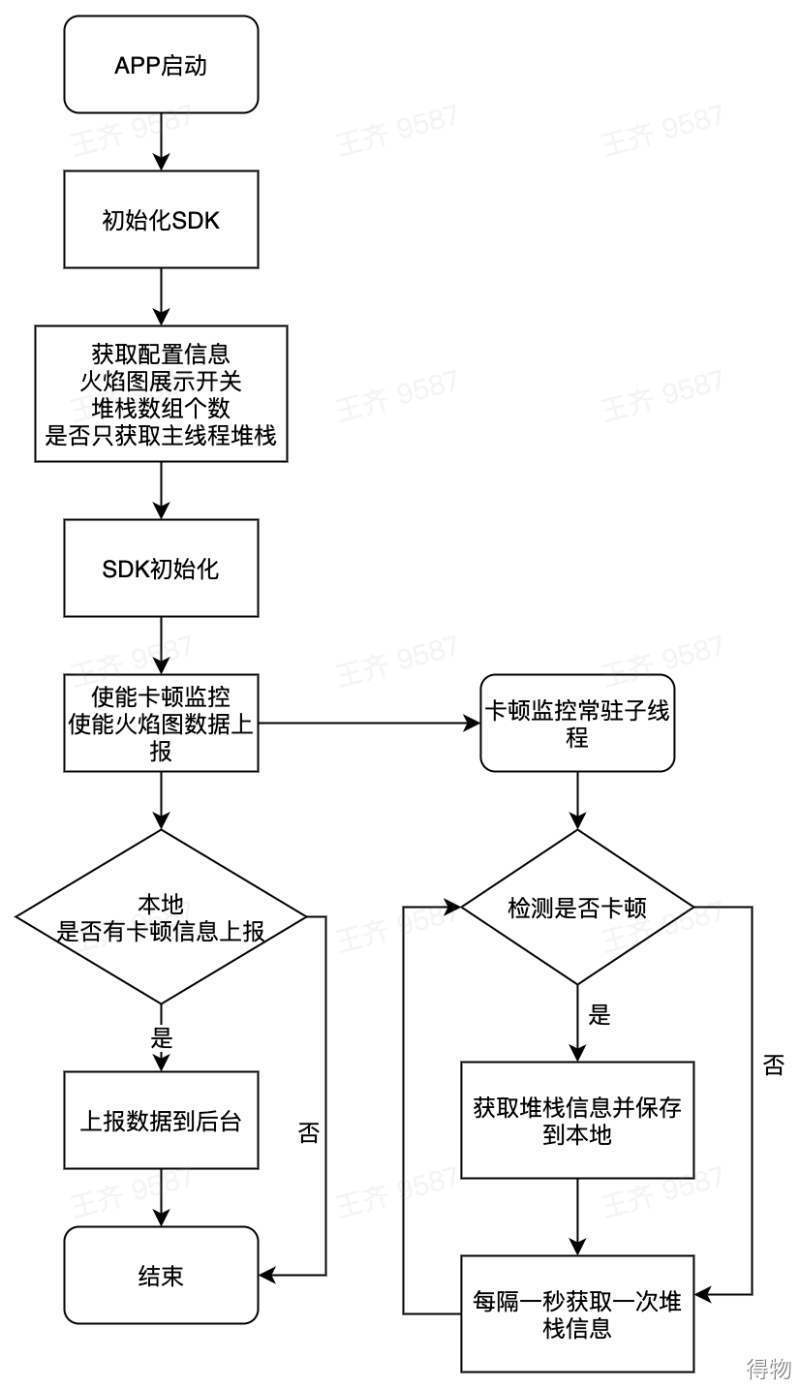
配置设计
在卡顿监控开启后,通过配置,分别设置来实现全部堆栈采集功能和最耗时堆栈采集。通过合理配置采样数据量及采集时间,使得数据采集量和数据可用性达到最优。
数据采集
当发生卡顿时,获取主线程堆栈信息,并获取所有堆栈信息列表,通过退火算法来过滤相同堆栈,并分析出最耗时堆栈信息。同时采样CPU信息,用以辅助分析卡顿时性能
数据结构设计
标识主线程堆栈,区分堆栈信息组和最耗时堆栈信息。调整优化上报信息,去除无用信息
整体设计流程图如下 :
符号化解析脚本
什么是符号化
在日常开发中,应用难免会发生崩溃。通常,我们直接从用户导出来的崩溃日志都是未符号化或者部分符号化的,是一堆十六进制内存地址的集合,可读性较差。未符号化或者部分符号化的崩溃日志对闪退问题的解决几乎毫无帮助,如下所示:
Last Exception Backtrace:0
CoreFoundation 0x1ca4cd27c 0x1ca3b5000 + 11475161
libobjc.A.dylib 0x1c96a79f8 0x1c96a2000 + 230322
CoreFoundation 0x1ca3ded94 0x1ca3b5000 + 1714123
TestBacktrace 0x102a47464 0x102a40000 + 297964
UIKitCore 0x1f6c86e30 0x1f63d3000 + 9125424只有经过符号化后的崩溃日志才能显示各个线程的函数调用,而不仅仅是毫无意义的虚拟内存地址。符号化后的崩溃日志如下所示, 此时,我们就能够直接从堆栈信息中知道应用 TestBacktrace 发生崩溃时的函数为 [AppDelegate Application:didFinishLaunchingWithOptions:],崩溃时函数所在文件为 AppDelegate.m,行号为23:
Last Exception Backtrace:0
CoreFoundation 0x1ca4cd27c __exceptionPreprocess + 2281
libobjc.A.dylib 0x1c96a79f8 objc_exception_throw + 552
CoreFoundation 0x1ca3ded94 -[__NSSingleObjectArrayI objectAtIndex:] + 1273
TestBacktrace 0x102a47464 -[AppDelegate Application:didFinishLaunchingWithOptions:] + 29796 (AppDelegate.m:23)4
UIKitCore 0x1f6c86e30 -[UIApplication _handleDelegateCallbacksWithOptions:isSuspended:restoreState:] + 411解析脚本功能
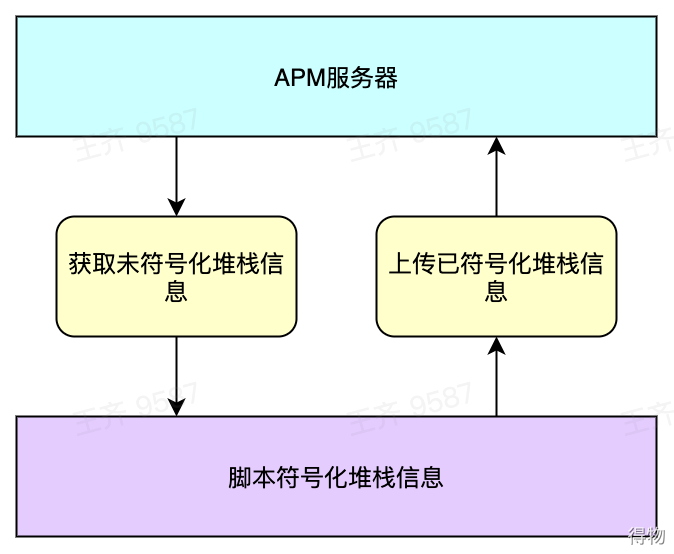
脚本解析数据
- 从APM服务器获取未解析数据,解析完后把数据上传到APM服务器
- 自动化解析堆栈信息,通过重组并利用App符号表和系统符号表来解析堆栈信息
- 解析堆栈数据结构,并对堆栈信息组和最耗时堆栈分别解析。
- 解析脚本设计
- 符号化脚本服务与APM服务交互流程如图所示
服务端设计
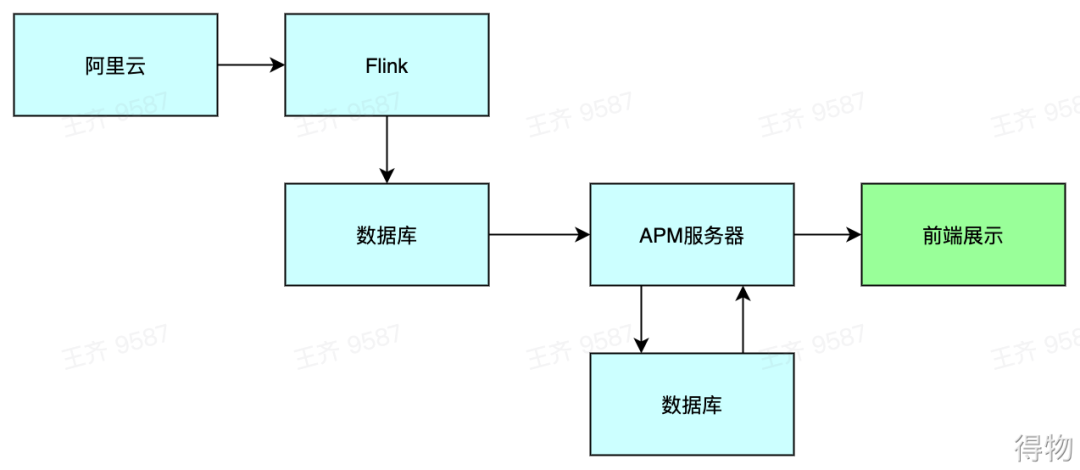
服务端工作流程如下图,Flink实时同步阿里云数据,并存入到数据库中。APM服务器则从数据库中获取数据,经过符号化脚本解析后,再存回到数据库中。当前端展示时,APM服务器再从数据库中获取数据,并传输到前端中展示出来。数据流如下图:
联调测试及性能测试
得物性能测试(CPU/内存)
测试设备:iPad mini 5
实测数据如下列表:
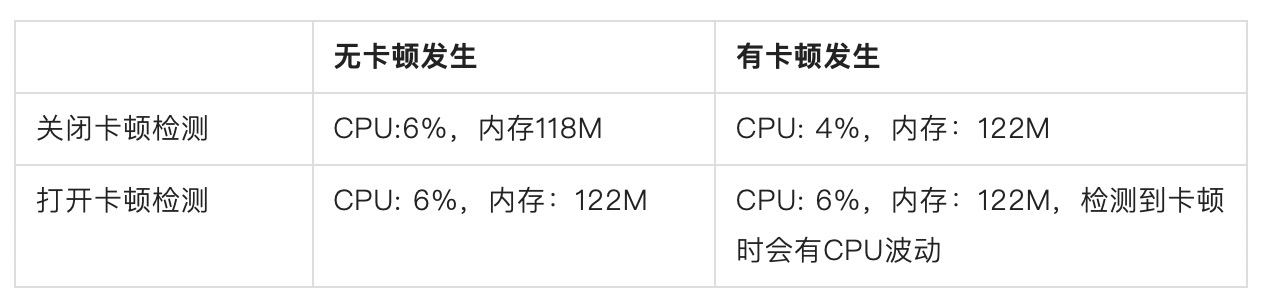
以下三种情况,其CPU占用和内存占用大体相同,如下所示
1. 关闭卡顿检测,并无卡顿发生
2. 关闭卡顿检测,并有卡顿发生
3. 开启卡顿检测时,并无卡顿发生
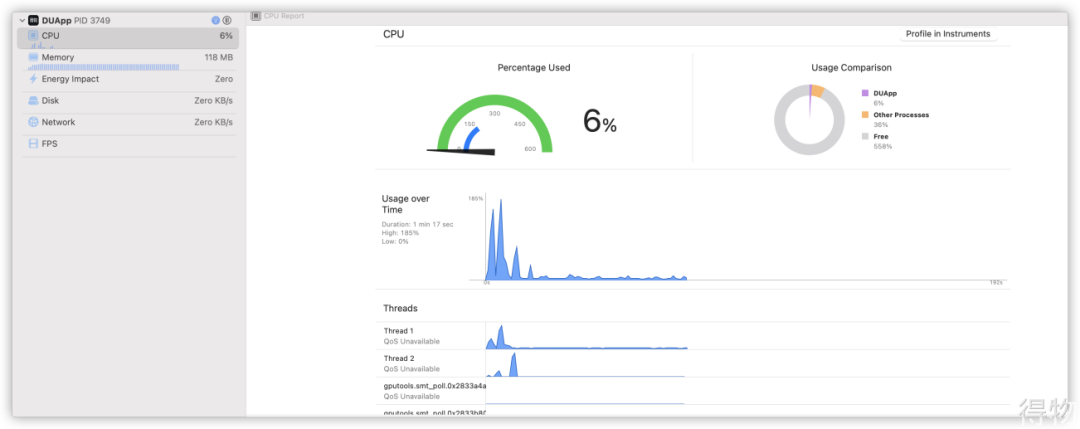
4. 开启卡顿检测时,并有卡顿发生时
参数:总体CPU和内存占比,CPU: 6%,内存:122M
说明: 在首页延迟25s,执行卡顿方法。检测到卡顿时,CPU有较高的瞬时波峰。
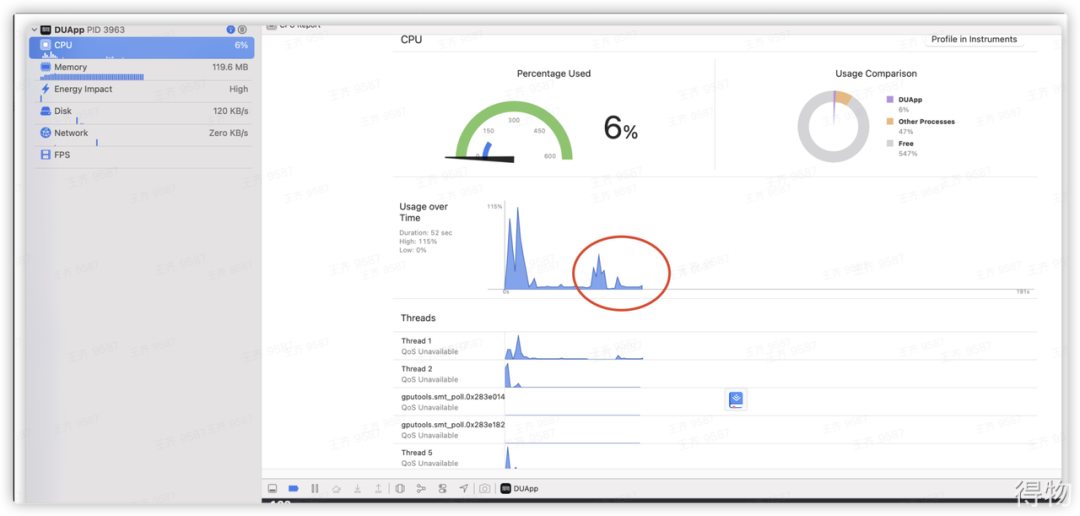
对线程占用CPU情况分析
对卡顿监控子线程进行分析,从图片可以看下如下两点
1. 检测到运行卡顿后,CPU会有个脉冲式的高CPU占用。如下面第一张图中红框内所示。
2. 在第二张图中,线程block_monitor_123,为检测卡顿子线程,当检测到卡顿时,会有脉冲式CPU占比,未检测到卡顿时,CPU占比比较小。
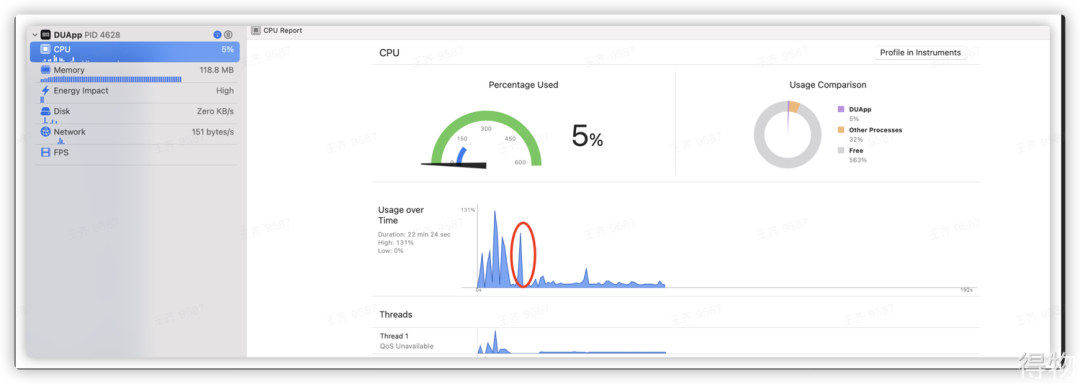
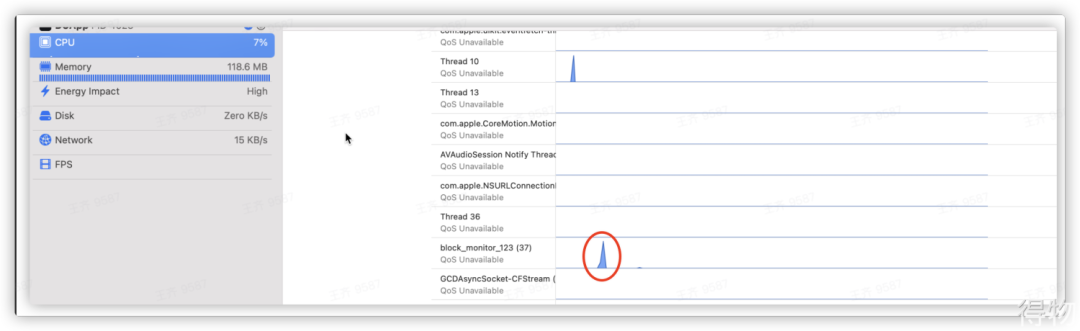
卡顿检测线程,本身为非连续高频检测,最小检测时间为1秒,当子线程多次检测到卡顿后,有以下两种情况。
1. 如果堆栈信息相同,则只会有第一次计算最耗时堆栈信息和获取全部堆栈信息,并写入缓存,这部分动作最耗性能。其它次,则只取主线程堆栈信息,而且会由退火算法不断地减少读取次数;
2. 如果堆栈信息不同,则会计算最耗时堆栈信息和获取全部堆栈信息,并写入缓存。
由此看,虽然卡顿检测线程不会占用太长时间CPU,但其处理堆栈信息部分和写入缓存部分还是存在一定的性能损耗的,通过上面二张图对比发现,子线程占用CPU和主线程卡顿占用CPU重合,这样就加剧了瞬时的性能损耗。
性能优化
性能优化策略,主要是通过延迟子线程执行损耗性能任务的时机,来降低CPU瞬时损耗。
在子线程中任务分成两部分,第一部分是是获取检测主线程卡顿和主线程堆栈信息。第二部分是计算最耗时堆栈信息和获取全部堆栈信息,并存入缓存。其中损耗CPU的是第二部分功能。
针对主线程卡顿和卡顿子线程叠加情况,本方案设计了延迟子线程损耗性能部分功能的执行操作。
1. 开劈线程block_monitor_deal_data,每隔三秒执行一次
2. 判断主线程Runloop状态是否进入kCFRunLoopBeforeWaiting状态,CPU使用率小于40%,缓存队列中存在未处理堆栈信息
3. 当条件都满足时,处理子线程的第二部分任务功能。
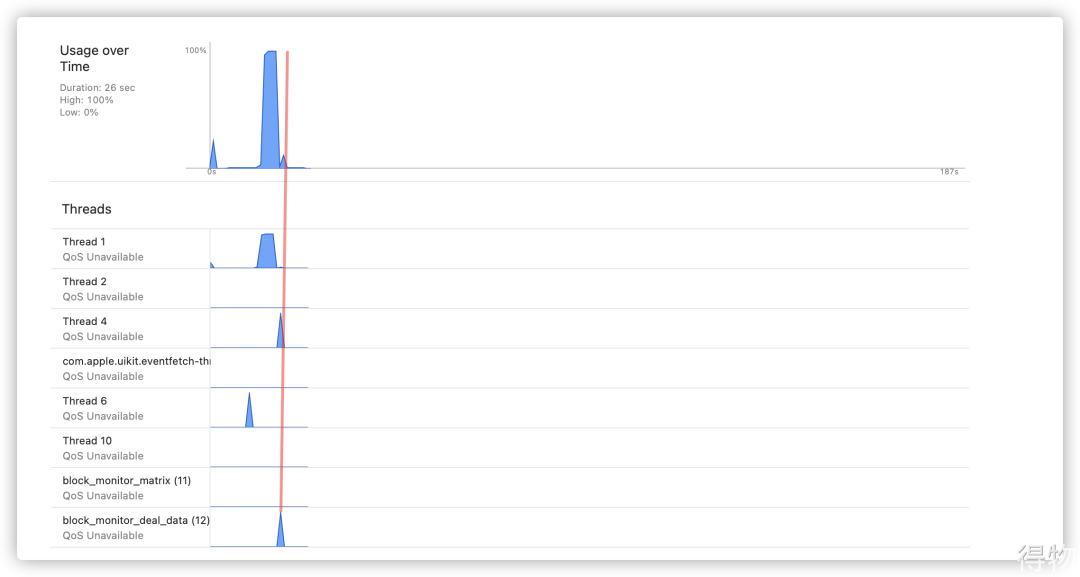
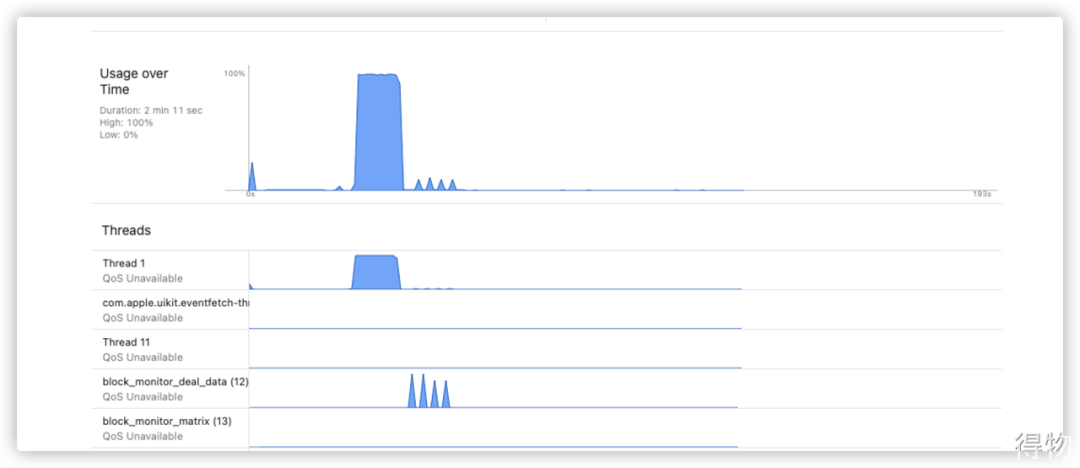
如下测试1和测试2中,明显可以看到,子线程对CPU的瞬时占用与主线程卡顿占用CPU的波形没有叠加。
测试1:队列中只有一个堆栈信息时
测试2:队列中有多条堆栈信息时
总结
本文介绍了iOS卡顿监控策略,包括卡顿检测原理,整体架构方案的设计,平台数据展示,性能优化等,在实施过程中也借鉴了业内优秀方案的思路,站在巨人的肩膀上实现了自己的一套整体实现方案。后续还有很多优化点,比如本文只实现的监测主线程阻塞导致卡顿情况,还有其他导致卡顿情况未实现,符号化脚本也可以做成专用脚本服务等。有了起点后,在此基础上不断优化,团队的技术才能更好地发展,不断地向前。

